
WORKS
- HOME
- WORKS LIST
- 会議録の検索性を根本から変える 業界特化型NLPによる自動ハッシュタグ付与システムの開発
会議録の検索性を根本から変える 業界特化型NLPによる自動ハッシュタグ付与システムの開発

リード文
専門性の高い事業領域を持つお客様の組織では、日々行われる会議の記録がテキスト・音声の双方にわたって継続的に蓄積されていました。しかし、その膨大なデータを横断的に活用できる検索基盤が整っておらず、業界固有の専門用語や略語が標準的なNLPエンジンでは正確に処理されないため、担当者が必要な情報を探し当てるために要する時間とコストが業務上の課題となっていました。
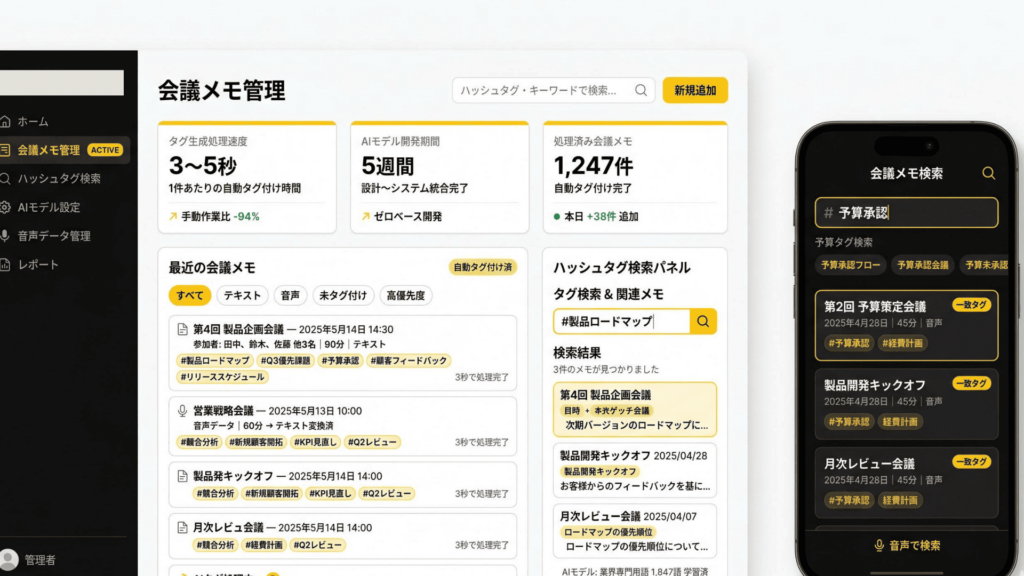
AMELAは、お客様の会議データそのものを学習の起点とするアプローチを提案。テキスト・音声双方のデータを収集・構造化し、業界特化型の自然言語処理モデルをゼロからファインチューニングすることで、会議メモへの自動ハッシュタグ付与を実現するAIモジュールを開発しました。
その結果、会議内容の解析・タグ生成を3〜5秒以内で処理できる体制を整備。AIモジュールの設計から既存システムへの統合完了まで、わずか5週間で対応しました。
プロジェクト概要
| 項目 | 内容 |
| 業界 | エンタープライズ / 専門職種向け業務支援 |
| 開発カテゴリー | 業務システム / AI・自然言語処理 |
| プラットフォーム | Web |
| 技術領域 | 自然言語処理(NLP)、機械学習モデル、音声テキスト変換(STT)、Elastic Search |
| 主な機能 | 自動ハッシュタグ生成、会議メモ要約、専門用語対応検索 |
| バックエンド | Node.js / REST API |
| クラウド | AWS |
| 開発期間 | 5週間(AIモジュール設計・開発〜システム統合完了) |
| チーム構成 | 4名 |
お客様の課題
蓄積される会議記録、活かしきれない専門知識
お客様の組織では、複数の部門・拠点にわたる会議がテキストメモ・音声録音の形で継続的に記録されていました。記録量の増加とともに、過去の議事録や会議内容を検索・参照するニーズも高まっていましたが、既存の検索環境はその要件を十分に満たせていませんでした。
問題の核心は、お客様の業界に固有の専門用語・略語・慣用表現にありました。汎用的な自然言語処理エンジンはこれらを一般的な語彙として処理するため、検索クエリと実際の会議内容がうまく結びつかないケースが頻発。担当者が手作業で関連文書を探し当てる工数が、業務上の無視できないコストとなっていました。
加えて、テキスト形式とは別に音声データとして記録された会議も混在しており、統一的な検索・ナレッジ管理の仕組みが整っていないことが、組織横断的な情報活用を阻む構造的な課題にもなっていました。
主な課題は以下の通りです。
- 業界固有の専門用語・略語が汎用NLPで正しく処理されず、検索精度が実用レベルに達していなかった
- テキスト・音声と形式の異なる会議データが分散管理されており、一元的に検索・活用できる環境が整っていなかった
- 会議記録へのタグ付けや分類が手作業・属人的な運用に依存しており、担当者の工数を圧迫していた
- 組織に蓄積されたナレッジを意思決定や業務改善に活かす仕組みが不足していた
お客様の要件
本プロジェクトにおいて、お客様から設定された主な要件は以下の通りです。
- 業界固有の専門用語を正確に認識し、会議メモに適切なハッシュタグを自動付与できること
- テキスト形式だけでなく、音声形式の会議データにも対応できること
- 生成されたタグを通じて、関連する会議記録を素早く横断検索できること
- 既存の会議管理システムや業務フローと摩擦なく統合できること
- 業界・用語の変化に応じてモデルを継続改善できる、柔軟な学習基盤を備えること
AMELAの解決策

AMELAは、汎用的なNLPモデルをそのまま転用するのではなく、お客様の会議データそのものを学習の起点とするカスタムファインチューニングアプローチを提案しました。
「業界の言葉を知っているAI」を作るためには、その業界の言葉が実際に使われているデータが必要です。AMELAはまず、お客様が保有するテキスト・音声双方の会議記録を網羅的に収集・整備することに着手。その上でモデルの設計・学習・評価を短いサイクルで繰り返す体制を整え、実用に耐える精度とレスポンス性能の両立を目指しました。
1. 会議データの収集・構造化
組織内に蓄積されたテキスト形式の会議メモと、音声形式で記録された会議データをクローリング・収集しました。音声データは文字起こし処理(STT)を経た上でテキストデータと統一フォーマットに整形し、業界固有の語彙リストとあわせてモデル学習に適した構造化データとして整備しました。
2. 業界特化型NLPモデルのファインチューニング
収集・整備した会議データをもとに、汎用自然言語処理モデルへのファインチューニングを実施しました。業界特有の表現が文脈に応じて正確に認識・分類されるよう、複数の評価指標を設定しながら学習と検証を繰り返しました。
開発過程では、専門用語の認識精度と推論レイテンシのバランス調整が技術的な課題のひとつとなりました。モデルの軽量化と精度維持を両立させる構成を選択することで、実運用で求められる3〜5秒以内のレスポンス性能を実現しています。
3. 自動ハッシュタグ生成機能の実装
ファインチューニング済みのNLPモデルを活用し、会議メモを解析して関連性の高いハッシュタグを自動生成するモジュールを開発しました。タグの命名規則や粒度はお客様の運用方針に合わせて設計し、現場の担当者が違和感なく利用できる形での実装を実現しました。生成されたタグはElastic Searchと連携し、全文検索・関連文書レコメンド機能へとシームレスに接続されます。
4. 既存システムへの統合と拡張基盤の整備
開発したAIモジュールはREST APIとして設計し、お客様の既存会議管理システムへのスムーズな統合を実現しました。また、業界の変化や新語の追加に応じてモデルを再学習・更新できる柔軟な構成としており、導入後も継続して精度を高められる運用基盤として整備しています。
導入効果

本システムの導入により、お客様は蓄積された会議データをより効率的に検索・活用できる体制を整えられました。
会議メモの解析・タグ生成を3〜5秒で処理
AIモジュールによるハッシュタグ自動付与を3〜5秒以内で完了できる体制を実現しました。これまで担当者が手作業で行っていた分類・タグ付け作業を大幅に削減し、本来注力すべき業務への集中を支援しています。
5週間での稼働開始により、現場改善を早期に実現
AIモジュールをゼロから設計・開発し、既存システムへの統合まで5週間で完了。お客様は早期に運用を開始でき、AIを活用したナレッジ管理の効果を速やかに享受できる体制を得ることができました。
組織ナレッジへのアクセス性が向上
適切なハッシュタグによって会議記録が構造化されたことで、担当者が必要な情報へ迅速にアクセスできるようになりました。これまで”埋もれていた”過去の会議内容が検索可能な組織知識として再活用されはじめており、意思決定や業務改善における情報活用の質が向上しています。
まとめ
本プロジェクトでは、業界固有の専門用語への対応という高い技術的ハードルに対し、お客様の会議データそのものを学習基盤として活用するアプローチで応えました。
汎用技術の転用ではなく、お客様の業務文脈を深く理解した上での設計・開発によって、「実務で使える精度」と「業務に溶け込む速度」を両立したAIシステムの構築を支援しました。
今後は蓄積データを活用したモデルの継続的改善と、検索・ナレッジ活用基盤のさらなる拡充を見据えたフェーズ2への展開を予定しています。
AMELAのAI・システム開発サービスについて、詳しくはサービスページをご覧ください。自然言語処理・業務AIの開発に関してご関心のある方は、まずはお気軽にご相談ください。
