
WORKS
- HOME
- WORKS LIST
- AI技術を活用した横断的データ分析・検索プラットフォームの構築 ― 多形式ドキュメントからの効率的な情報抽出を実現
AI技術を活用した横断的データ分析・検索プラットフォームの構築 ― 多形式ドキュメントからの効率的な情報抽出を実現
カテゴリ
- 業界(Industry): 業界横断
- 開発カテゴリー(Solution): AIソリューション開発(新規追加提案)
- 技術スタック(Tech Stack): AI/ML(NLP / OCR / LLM / VLM / RAG Pipelines / GraphRAG)
- プラットフォーム(Platform): Web
概要
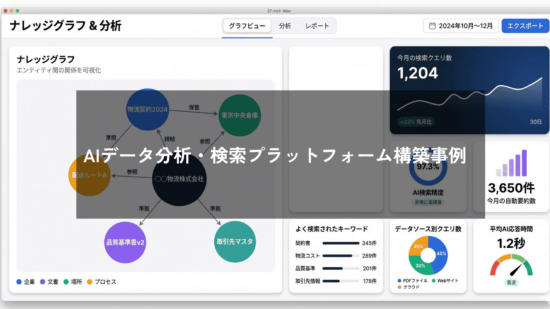
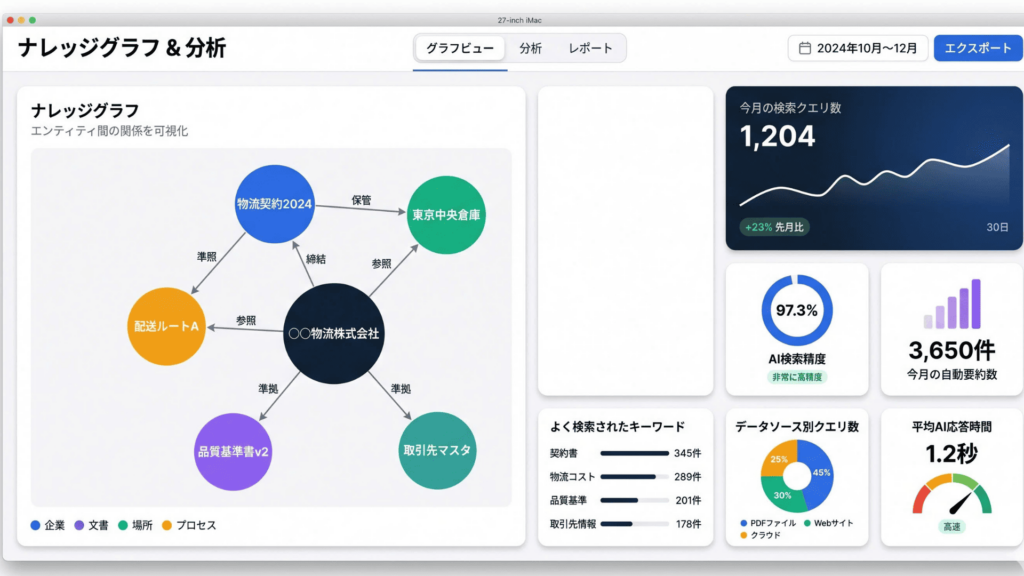
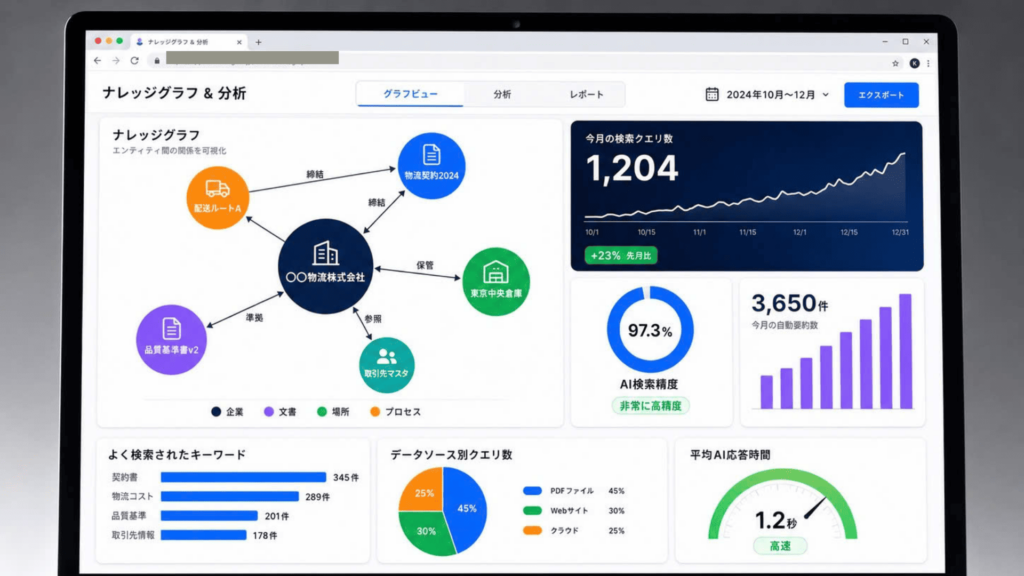
本事例は、複数の形式・ソースに分散した社内データをAIによって統合的に分析・検索し、ユーザーが必要な情報へ迅速かつ正確にアクセスできる環境を構築したプロジェクトです。クライアントは、膨大なドキュメントと非構造化データの活用に深刻な課題を抱えていました。AMELAは、NLP・OCR・LLM・VLMといった最新のAI技術と、RAGパイプラインおよびGraphRAGアーキテクチャを組み合わせ、文脈理解型の質問応答、多形式ドキュメント解析、コンテンツベースのデータ検索を実現する統合プラットフォームを約3ヶ月で構築。検索精度の飛躍的な向上と、手作業時間の大幅な削減を実現しました。
クライアントが抱えていた課題
クライアントは、業務上膨大なドキュメントおよびデータを日常的に取り扱う企業です。情報量と種類の拡大が続く中、蓄積されたデータ資産を十分に活用できていない状況が業務全体のボトルネックとなっていました。
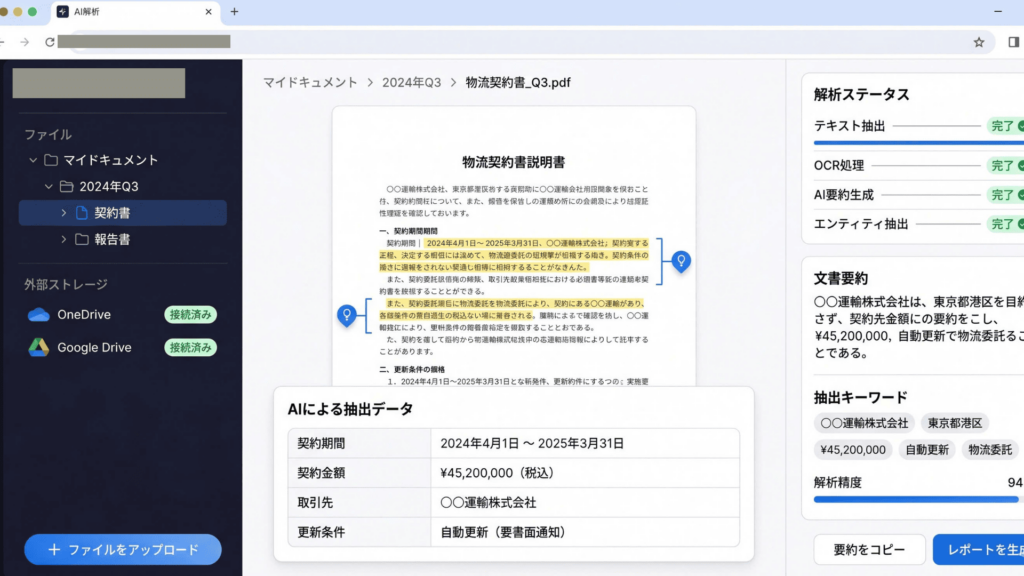
- 膨大なドキュメントからの情報探索に多大な時間を要する 契約書、報告書、技術資料、画像データなど社内に蓄積された情報量が膨大であり、必要な情報を見つけ出すだけで多くの工数が消費されていました。
- データ形式と保管場所のばらつきによる検索効率の低下 PDF、Word、Excel、画像といった多様な形式のデータが、ローカル環境、OneDrive、Google Driveなど複数の場所に分散しており、横断的な検索が困難な状況でした。
- 手作業による内容確認に起因するヒューマンエラー ドキュメントの内容を人手で確認・要約する作業が業務の大半を占めており、見落としや誤読といったヒューマンエラーが発生しやすい状況にありました。
- 非構造化データからの知見抽出の困難さ 業務上重要な情報の多くが、自由記述テキストや画像などの非構造化データとして存在しており、これらから業務に活用できる知見を引き出すことが困難でした。
- 意思決定に必要な情報を迅速に可視化できない 経営層や現場の意思決定に必要な情報をタイムリーに集約・整理できず、判断スピードに影響を及ぼしていました。
クライアントの要件
クライアントが本プロジェクトに求めた要件は、以下の通りです。
- 複数形式・複数ソースのデータを横断的に検索できる仕組みの構築
- 自然言語による質問に対し、文脈を理解した的確な回答を返すAI機能の実装
- PDF、Word、Excel、画像など多形式ドキュメントからの情報抽出
- クライアントWebサイトおよびクラウドストレージ(OneDrive、Google Drive)との連携
- 要約および主要データの自動生成による業務効率化
- 高い精度と応答速度を両立した実用的なシステム
AMELAのソリューション
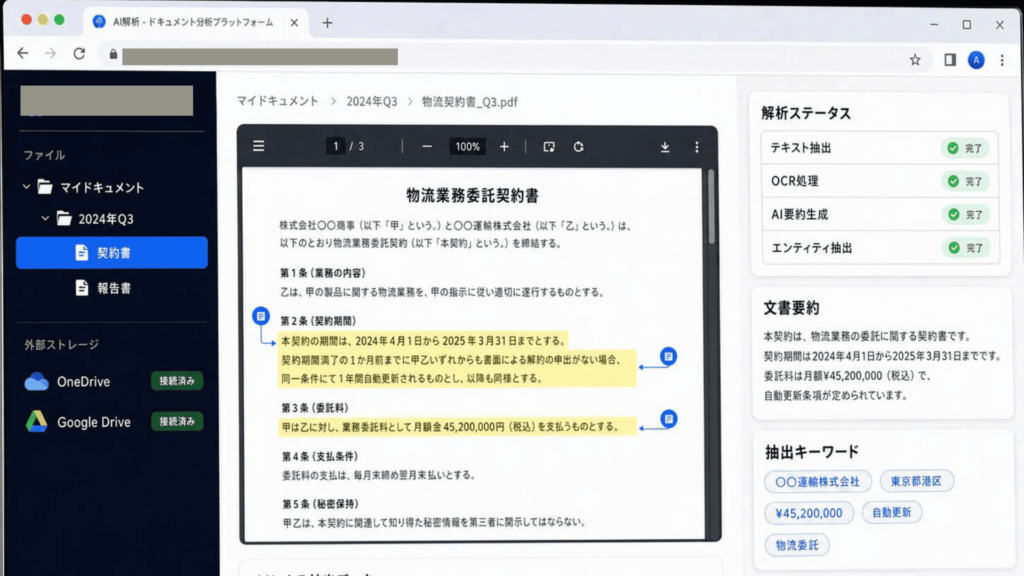
AMELAは、最新のAI/ML技術を組み合わせ、「文脈理解」「ドキュメント解析」「コンテンツ検索」の3つの機能を統合したAIプラットフォームを設計・構築しました。プロジェクトは約3ヶ月の短期間で、以下の4つのフェーズで段階的に推進しました。
フェーズ1:要件定義と技術アーキテクチャ設計
クライアントの業務フロー、扱うデータの種類・規模・保管環境を詳細にヒアリングし、優先すべきユースケースと機能要件を明確化しました。これに基づき、LLMを中核に据えたRAG(Retrieval Augmented Generation)パイプラインと、データ間の関係性を考慮するGraphRAGアーキテクチャを組み合わせた最適な技術構成を設計しました。
フェーズ2:文脈理解型の質問応答エンジンの開発
NLPとLLMを活用し、自然言語による質問に対して文脈を踏まえた的確な回答を返す質問応答エンジンを開発しました。定型的なFAQ形式の質問だけでなく、曖昧な表現や複雑な意図を含む非構造化クエリにも対応できるよう、RAGパイプラインを介して社内データを動的に参照する仕組みを実装しています。
フェーズ3:多形式ドキュメント解析モジュールの実装
OCRおよびVLM(Vision Language Model)を組み合わせることで、PDF、Word、Excel、画像など多様な形式のドキュメントから情報を読み取り・抽出できる解析モジュールを構築しました。あわせて、長文ドキュメントの自動要約や、金額・日付・固有名詞などの主要データを自動抽出する機能を実装し、人手による確認作業を大幅に削減しています。
フェーズ4:コンテンツベースのデータ検索とソース連携
クライアントWebサイトのコンテンツをインデックス化し、サイト内情報に基づく正確な回答を提供する機能を実装しました。同時に、OneDriveやGoogle Driveに保存された共有ドキュメントへ参照・処理を行うコネクタを開発し、社内外に散在する情報を一元的に活用できる環境を整えています。これら全ての機能はGraphRAGアーキテクチャによって統合され、データ間の関係性を踏まえた高精度な検索・分析を実現しました。
なお、本プロジェクトを含むAI関連の開発支援は、AMELAが提供するAIソリューション開発サービスの一環として、お客様の業種や課題に応じた柔軟なアプローチで展開しています。
採用したテクノロジースタック
- NLP(自然言語処理)
- OCR(光学文字認識)
- LLM(大規模言語モデル)
- VLM(Vision Language Model)
- RAG Pipelines
- GraphRAG
導入効果
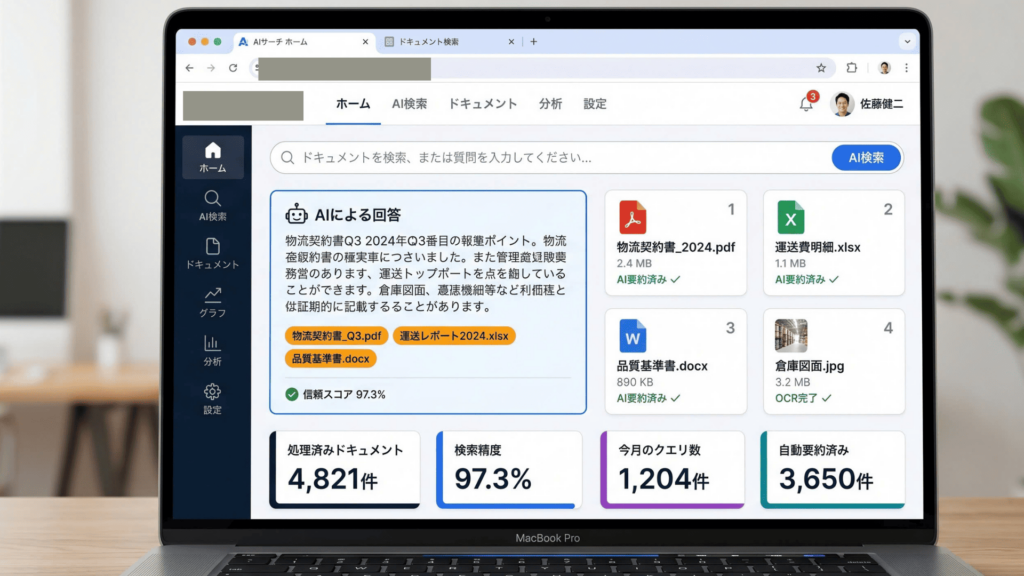
本プロジェクトを通じて、クライアントは以下の成果を獲得しました。
- 情報検索のスピードと精度が大幅に向上 散在していた多形式データを横断的に検索できるようになり、必要な情報へのアクセスが格段に迅速化されました。文脈理解型のAIにより、検索結果の精度も飛躍的に向上しています。
- ドキュメント読解にかかる手作業時間の大幅削減 OCRおよび自動要約・抽出機能の活用により、従来人手で行っていたドキュメント内容の確認・整理作業が大幅に自動化され、業務負荷が顕著に軽減されました。
- 構造化インサイトによる意思決定の高度化 ファイルやWebサイトから抽出された構造化インサイトが提供されることで、経営層や現場における意思決定がデータドリブンかつ迅速に行えるようになりました。
まとめ
本事例では、最新のAI技術を組み合わせ、多形式・多ソースのデータを横断的に活用できるプラットフォームをわずか3ヶ月で構築し、クライアントの情報活用基盤を一気に高度化することに成功しました。NLP、OCR、LLM、VLMを統合し、RAGおよびGraphRAGアーキテクチャを採用することで、単なる検索ツールにとどまらず、文脈を理解した上で意思決定を支援する「ナレッジ活用基盤」としての価値を実現しています。
AMELAは、生成AIおよびナレッジマネジメント領域における豊富な実装ノウハウを有し、業務効率化、社内検索、AIアシスタント構築、非構造化データ活用など、お客様の課題に応じた柔軟な提案と開発が可能です。AIソリューションの導入に関するご相談は、お問い合わせフォームよりお気軽にご連絡ください。
